|





| |
Document Image Analysis (DIA) Research:
|
|
 |
| |
|
 |
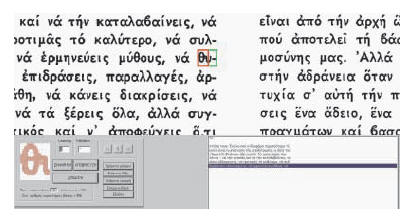
Page Segmentation:
Automatic extraction of the main document image components (text, titles,
images, captions, graphics, lines, special symbols) [ ], segmentation area
location using isothetic polygons [], newspaper page segmentation into
specific items (main titles, head-lines, over-titles, sub-titles,
references), article identification and reconstruction [],
combining complementary techniques for document image segmentation []. ], segmentation area
location using isothetic polygons [], newspaper page segmentation into
specific items (main titles, head-lines, over-titles, sub-titles,
references), article identification and reconstruction [],
combining complementary techniques for document image segmentation []. |
|
 |
|
Competitions:
-
First International
Newspaper Segmentation Contest []
-
ICDAR 2003 Page
Segmentation Competition []
-
ICDAR2005 Page
Segmentation Competition []
-
ICDAR2007 Page
Segmentation Competition []
-
ICDAR2007 Handwriting
Segmentation Contest []
-
ICDAR2009 Handwriting
Segmentation Contest [
]
-
ICDAR 2009 Document Image
Binarization Contest (DIBCO 2009) [
]
-
ICFHR 2010 Handwriting
Segmentation Contest []
-
H-DIBCO 2010 – Handwritten
Document Image Binarization Competition []
-
ICDAR 2011 Document Image
Binarization Contest (DIBCO 2011) []
-
ICDAR 2011 Writer
Identification Contest []
-
ICFHR 2012 Competition on
Handwritten Document Image Binarization (H-DIBCO 2012) []
-
ICFHR2012 Competition on
Writer Identification - Challenge 1: Latin/Greek Documents []
-
ICDAR 2013 Competition on
Writer Identification Document Analysis and Recognition []
-
ICDAR 2013 document image
binarization contest (DIBCO 2013) []
-
ICDAR 2013 Document Image
Skew Estimation Contest (DISEC 2013) []
-
ICDAR 2013 Handwriting
Segmentation Contest []
-
ICFHR2014 Competition on
Handwritten Document Image Binarization (H-DIBCO 2014) []
-
ICFHR 2014 Competition on
Handwritten KeyWord Spotting (H-KWS 2014) []
-
ICFHR2016 Handwritten
Keyword Spotting Competition (H-KWS 2016) []
-
ICFHR2016 Handwritten
Document Image Binarization Contest (H-DIBCO 2016) []
-
ICDAR2017 Competition on
Document Image Binarization (DIBCO 2017)
-
cBAD: ICDAR2017
Competition on Baseline Detection
-
ICDAR2017 Competition on
Historical Document Writer Identification (Historical-WI)
|
|


 |
|
Line and Table Detection:
Automatic table detection in document images, morphological operations in
order to connect line breaks and to enhance line segments, horizontal and
vertical line detection, image/text areas removal, detection of line
intersections, table reconstruction. []
|
|
 |
|